

24.03.2021
6 minutes de lecture




Les décideurs publics manquent aujourd’hui d’outils pour évaluer l’impact du trafic routier sur la qualité de l’air et éclairer les décisions à prendre pour réduire les émissions de polluants. Des équipes IFPEN ont mis au point un outil qui permet, grâce aux données remontées depuis des véhicules connectés (« Floating Car Data » ou FCD), d’évaluer la pollution émise par des comportements de conduite caractéristiques et in fine de cartographier avec précision les émissions polluantes des véhicules sur différents segments routiers d’un territoire.
Quand émissions et accélérations vont de pair
Les émissions polluantes des véhicules dépendent bien sûr des technologies du groupe motopropulseur mais aussi des conditions de conduite, elles-mêmes liées au style de conduite, aux aménagements de voirie et à la régulation du trafic. Ces conditions constituent donc autant de leviers d’action pour les décideurs publics, lesquels cependant manquent aujourd’hui d’outils efficaces pour évaluer l’impact réel du trafic routier sur la qualité de l’air.
L’évaluation correcte des émissions polluantes des véhicules passe par une estimation fiable de l’impact des conditions de conduite sur les points de fonctionnement du moteur, ceux-ci dépendant des caractéristiques du véhicule, mais aussi des accélérations et de la pente de la route.
Le comportement de conduite, cela s’apprend
La diffusion des véhicules connectés capables de remonter des données acquises pendant la conduite (« Floating Car Data » ou FCD) permet d’apprendre le comportement de conduite réel dans différentes conditions de trafic ou d’aménagement de l’infrastructure routière. Ces informations sont aujourd’hui facilement accessibles grâces aux systèmes d’information géographique (SIG).
Les équipes IFPEN ont donc proposé une méthode d’apprentissage du comportement de conduite dynamique [1] (prise en compte des accélérations) qui permet d’associer des profils de vitesse statistiquement représentatifs aux différentes situations de conduite réelle, telle qu’impactée par l’infrastructure, la congestion et les mesures de régulation du trafic. Le modèle illustré en Figure 1 se base sur des outils de « machine learning », et plus précisément sur des combinaisons de techniques d’apprentissage supervisé (par ex. réseaux de neurones et forêts aléatoires1) et non-supervisé (clustering2), afin de reproduire les comportements caractéristiques des conducteurs dans les différentes situations de conduite réelle.
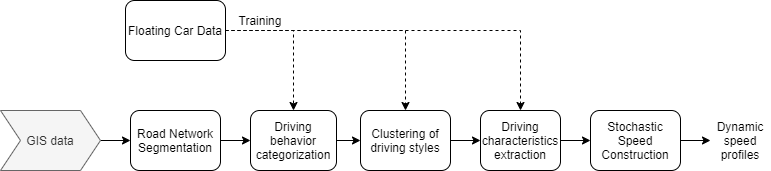
Ensuite, un processus de Markov3 permet de générer des profils de conduite avec une variabilité statistiquement représentative du style de conduite, tel qu’observé dans les FCD.
La formation des émissions polluantes passée au microscope
Les profils de vitesse ainsi générés sont évalués au moyen d’un modèle d’émissions polluantes développé par IFPEN et s’appuyant sur ses moyens d’essai et sur son savoir-faire en matière de caractérisation des moteurs et des systèmes de dépollution. Une chaîne de modélisation complète et validée étape par étape permet par conséquent de décrire les phénomènes qui vont de la conduite, à la combustion et aux polluants émis dans l’environnement (Figure 2).
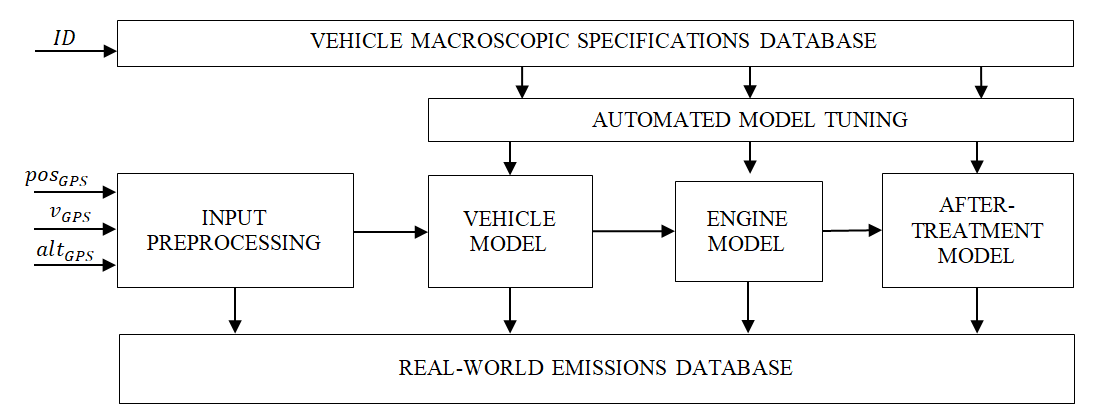
L’approche de modélisation proposée dans ce travail vise à trouver un compromis entre la précision et la simplicité d’expression mathématique requise pour la rapidité de calcul. Des modèles 0D sont donc utilisés avec les phénomènes thermiques et de mécanique des fluides caractérisés par des systèmes du premier ordre.
Enfin, la prise en compte de tout type de motorisation et de technologie de post-traitement, notamment Diesel Oxidation Catalyst (DOC), Diesel Particle Filter (DPF), Selective Catalytic Reduction (SCR), Lean NOx Trap (LNT) et Three-Way Catalyst (TWC), permet une adoption du modèle dans n’importe quelle zone géographique et quel que soit le parc automobile.
Les émissions polluantes à la carte
L’étape finale de la méthode proposée consiste à représenter sur une carte les émissions polluantes des véhicules par segment routier. L’objectif est de fournir aux pouvoirs publics et aux villes un outil précis de monitoring et de visualisation des émissions dues au trafic routier afin d’identifier efficacement les aménagements de voirie et les conditions de circulation ayant le plus d’impact sur la qualité de l’air locale [2]. La comparaison avec les outils classiques de l’état de l’art montre une amélioration significative de la précision et de la résolution temporelle et spatiale de la carte des émissions polluantes (Figure 3).
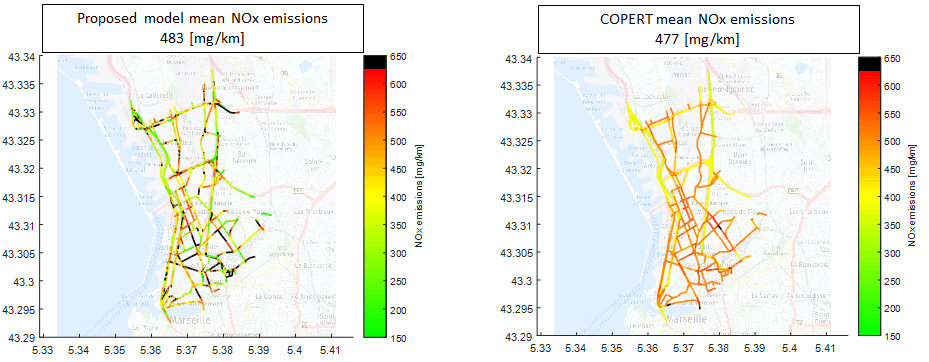
La diffusion croissante des véhicules connectés, agissant comme des capteurs mobiles, rendra l’approche proposée toujours plus efficace pour caractériser à haute résolution l’empreinte polluante du trafic routier.
1 L’algorithme des « forêts aléatoires » (ou « random forest » parfois aussi traduit par forêt d’arbres décisionnels) est un algorithme de classification qui réduit la variance des prévisions d’un arbre de décision seul, améliorant ainsi leurs performances. L’algorithme effectue un apprentissage en parallèle sur de multiples arbres de décision construits aléatoirement et entraînés sur des sous-ensembles de données différents.
2 Le clustering est une méthode en analyse des données qui vise à diviser un ensemble de données en différents sous-ensembles « homogènes », au sens où leurs données partagent des caractéristiques communes.
3 Processus stochastique qui vérifie deux conditions :
- l’état au temps t du processus ne dépend que de son état au temps t − 1
- la probabilité de passage d’un état i à un état j ne varie pas avec le temps
Les développements décrits ici s’appuient sur des compétences propres à la direction « Sciences et Technologies du Numérique » d’IFPEN : en analyse et traitement des données ainsi qu’en modélisation de systèmes complexes. La méthodologie explorée dans ce travail a permis d’alimenter la réflexion autour de plusieurs travaux de recherche fondamentale, dans le cadre de la démarche « verrous scientifiques » : en Flux massifs de données (VS4) et en Commande et optimisation (VS7). En particulier, une thèse en cours porte ainsi sur la « prédiction de profils de vitesse à partir de l’architecture d’un réseau routier, via des approches de deep learning » : elle permettra d’augmenter la représentativité des données actuelles afin de compléter des cartes d’émissions polluantes, de sécurité, de consommation énergétique, etc.
Références
[1] M. Laraki, G. De Nunzio, L. Thibault, “Vehicle speed trajectory estimation using road traffic and infrastructure information”, IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), 2020.
[2] G. De Nunzio, M. Laraki, L. Thibault, “Road Traffic Dynamic Pollutant Emissions Estimation: From Macroscopic Road Information to Microscopic Environmental Impact”, Atmosphere, 12, 53, 2021.
Contacts scientifiques : Giovanni De Nunzio, Mohamed Laraki, Laurent Thibault
Vous serez aussi intéressé par
Des modélisations dynamiques pour aider à (vraiment) atteindre la neutralité carbone
